
Compact and powerful, the OceanStor Dorado 18000 V6 data storage system fits into four units without counting disk shelves. For testing, we received a quad-controller system with four disk shelves, which have 60 1.92 TB NVMe Palm-Size form-factor drives installed.
With such a configuration, according to the sizer, it is possible to "squeeze" up to 1.5 million IOPS on a standard 70R/30W 8K profile, 100% random, 0% read Cache Hit. A single controller chassis is designed for the installation of four controllers. However, two chassis, i.e., up to eight controllers, can be connected to disk shelves via the 100Gb RDMA protocol without using external switches. And if you use additional switches, the number of controllers for one system can be increased to 32 to achieve maximum performance and capacity.
With such a configuration, according to the sizer, it is possible to "squeeze" up to 1.5 million IOPS on a standard 70R/30W 8K profile, 100% random, 0% read Cache Hit. A single controller chassis is designed for the installation of four controllers. However, two chassis, i.e., up to eight controllers, can be connected to disk shelves via the 100Gb RDMA protocol without using external switches. And if you use additional switches, the number of controllers for one system can be increased to 32 to achieve maximum performance and capacity.

The Dorado 18000 V6 supports triple cache mirroring. The cache is mirrored between three controllers. Since we had a four-controller system for testing, we tested the failure of three out of four controllers: first, two controllers simultaneously, and then one more. In an eight-controller configuration, the system is resilient to the failure of up to seven controllers.
In both cases, even if only one controller remains available, users can continue to work. This demonstrates the high level of fault tolerance and redundancy built into the Dorado 18000 V6 system, ensuring that it can maintain performance and data availability even in the face of multiple controller failures.
In both cases, even if only one controller remains available, users can continue to work. This demonstrates the high level of fault tolerance and redundancy built into the Dorado 18000 V6 system, ensuring that it can maintain performance and data availability even in the face of multiple controller failures.
Testing Beginnings
As a test platform for the Dorado 18000 V6, we used an AIX server with four 16 Gb Fibre Channel ports, connected through a SAN based on two Brocade GEN5 16 Gb switches. To conduct load testing of a real application on the test LPAR, we replicated a copy of a real database using Oracle DBMS tools. Synthetic tests were carried out using Vdbench.
This testing setup allows for a comprehensive evaluation of the Dorado 18000 V6's performance and capabilities in a real-world environment. By using both real application load testing and synthetic benchmarks, it is possible to get a better understanding of how the storage system will perform under various workloads and scenarios.
As a test platform for the Dorado 18000 V6, we used an AIX server with four 16 Gb Fibre Channel ports, connected through a SAN based on two Brocade GEN5 16 Gb switches. To conduct load testing of a real application on the test LPAR, we replicated a copy of a real database using Oracle DBMS tools. Synthetic tests were carried out using Vdbench.
This testing setup allows for a comprehensive evaluation of the Dorado 18000 V6's performance and capabilities in a real-world environment. By using both real application load testing and synthetic benchmarks, it is possible to get a better understanding of how the storage system will perform under various workloads and scenarios.
Results
The first and most important result obtained is the data storage efficiency ratio of 5.2:1. This was achieved for a single copy of a production database of 85 TB, which we placed on the Dorado V6.
Considering that the average efficiency ratio for databases is 3.5:1, the advanced deduplication and compression technology of Dorado V6 at the storage level places our test subject on par with industry leaders for this metric. This demonstrates the effectiveness of the Dorado 18000 V6 in optimizing storage space and reducing the required physical storage capacity, resulting in cost savings and improved resource utilization.
The first and most important result obtained is the data storage efficiency ratio of 5.2:1. This was achieved for a single copy of a production database of 85 TB, which we placed on the Dorado V6.
Considering that the average efficiency ratio for databases is 3.5:1, the advanced deduplication and compression technology of Dorado V6 at the storage level places our test subject on par with industry leaders for this metric. This demonstrates the effectiveness of the Dorado 18000 V6 in optimizing storage space and reducing the required physical storage capacity, resulting in cost savings and improved resource utilization.

The second important result is the time taken to close the operational day. The day-end closing procedure was run on the test server, and detailed application-level statistics were collected. Paired with the Huawei Dorado V6, the test server demonstrated a 6% faster operational day closing compared to the production server, which had disks allocated from a mature High-End All-Flash storage system from another manufacturer. Despite having four times fewer processor resources, the test server took longer to perform calculations. However, due to the overall acceleration of input/output, the procedure finished faster.
The impressive speed of the drives was able to compensate for the fewer computing resources. Indeed, on the Huawei Dorado V6, data sampling and sorting using disk space were up to 80% faster.
Synthetic Tests (Qualification)
In addition to the Dorado 18000 V6 NVMe, we were also able to test the younger models in the lineup - Dorado 3000 V6 SAS and Dorado 5000 V6 NVMe. The summary table of synthetic test results is as follows:
The impressive speed of the drives was able to compensate for the fewer computing resources. Indeed, on the Huawei Dorado V6, data sampling and sorting using disk space were up to 80% faster.
Synthetic Tests (Qualification)
In addition to the Dorado 18000 V6 NVMe, we were also able to test the younger models in the lineup - Dorado 3000 V6 SAS and Dorado 5000 V6 NVMe. The summary table of synthetic test results is as follows:
[At this point, a table summarizing the test results for the various models would be presented, comparing their performance metrics and other relevant data.]
The synthetic test results for the Dorado 18000 V6 NVMe, Dorado 3000 V6 SAS, and Dorado 5000 V6 NVMe provide valuable insights into the performance and capabilities of each model within the product lineup. Comparing these results allows potential users to better understand which model best suits their needs and requirements.
The synthetic test results for the Dorado 18000 V6 NVMe, Dorado 3000 V6 SAS, and Dorado 5000 V6 NVMe provide valuable insights into the performance and capabilities of each model within the product lineup. Comparing these results allows potential users to better understand which model best suits their needs and requirements.

When discussing the load profiles in the table:
All tests were performed with deduplication and compression enabled. The disk pool was initialized in RAID6. The relatively lower performance metrics for a single LUN can be explained by host-side limitations on the queue length. Using multiple hosts to access the LUN with a clustered file system can yield higher performance metrics. In this case, the storage system is not the bottleneck, as evidenced by the controller CPU load and low response time from the storage system.
Reaching the peak of performance
- Random – 65R/35W 8K, 100% random;
- Sequential – 256K, 100% write;
- БД1 Like – mix profile, 40KB random read, 24KB random write (90R/10W);
- БД2 Like — mix profile, 115KB random Read, 72KB random write (70R/30W);
- Vmware Like mix profile, 86KB random read, 11KB random write (46R/54W).
All tests were performed with deduplication and compression enabled. The disk pool was initialized in RAID6. The relatively lower performance metrics for a single LUN can be explained by host-side limitations on the queue length. Using multiple hosts to access the LUN with a clustered file system can yield higher performance metrics. In this case, the storage system is not the bottleneck, as evidenced by the controller CPU load and low response time from the storage system.
Reaching the peak of performance
To approach the calculated performance of the storage system, one test server was not enough. The test LPAR had only four 16 Gbit FC interfaces, which could provide input/output speeds of up to 6 GB/s in each direction.
To increase the load, we found two additional Huawei Taishan 2000 (Model 2280) test servers based on ARM. One server was equipped with a single two-port 16 Gb FC adapter, while the other had two such adapters. In total, we used 10 FC ports to connect the servers to the storage system.
By using this expanded testing environment with multiple servers, it is possible to push the storage system closer to its peak performance and better understand how it will perform under higher loads and more demanding scenarios. This approach provides a more comprehensive view of the system's capabilities and helps to identify any potential bottlenecks or limitations in real-world deployment:
To increase the load, we found two additional Huawei Taishan 2000 (Model 2280) test servers based on ARM. One server was equipped with a single two-port 16 Gb FC adapter, while the other had two such adapters. In total, we used 10 FC ports to connect the servers to the storage system.
By using this expanded testing environment with multiple servers, it is possible to push the storage system closer to its peak performance and better understand how it will perform under higher loads and more demanding scenarios. This approach provides a more comprehensive view of the system's capabilities and helps to identify any potential bottlenecks or limitations in real-world deployment:
- server #1, AIX 7.2, 4 x port FC 16Gb, 16 x LUN 500GB, RAID6;
- server #2, CentOS 7.6, 2 x port FC 16Gb, 16 x LUN 500GB, RAID6;
- server #3, CentOS 7.6, 4 x port FC 16Gb, 16 x LUN 500GB, RAID6.
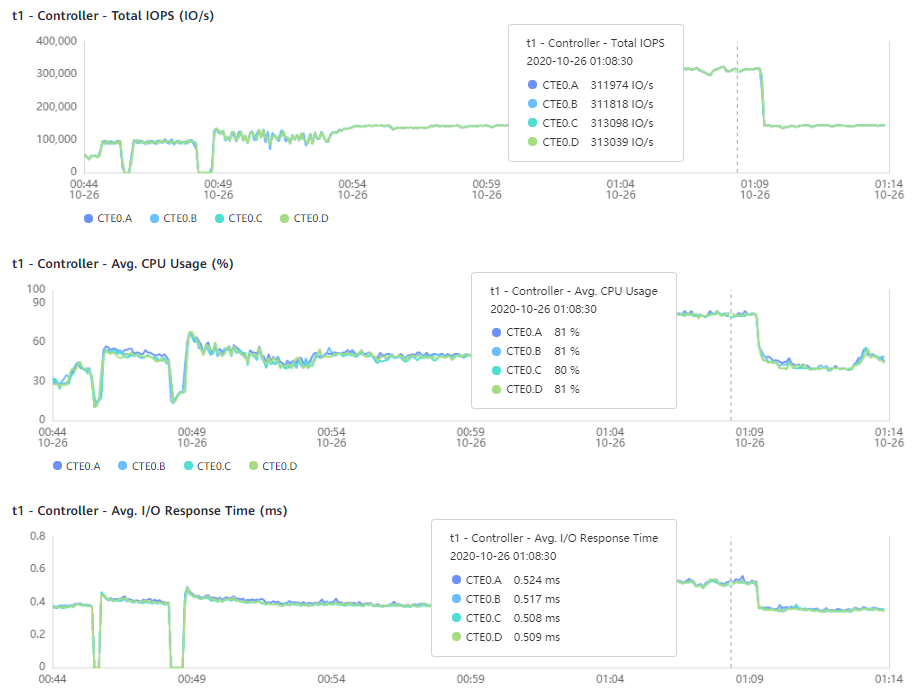
As a result of this load test, we achieved 1.3 million IOPS, 9.9 GB/s with an average response time on the array of 0.53 ms, which is very close to the calculated maximum values from the sizer. Based on the array latency and 80% controller CPU utilization in the graphs below, we can conclude that there is a performance reserve of about 15% for our configuration.
Load Balancing
The built-in load balancing feature automatically distributes the workload across all controllers and I/O modules. In Dorado V6, LUNs do not require binding to a controller, and the load on a single LUN is automatically distributed among all controllers and I/O modules.
To evaluate its effectiveness, we presented the test server with four LUNs and sequentially excluded one LUN from the system. During this process, all front-end interfaces and storage system controllers were utilized evenly.
System Component Failures
During the series of resilience tests, we created a background load on the array using Vdbench, with a rate of approximately 1 GB/s. The performance of the array was practically unaffected by either the failure of a single power line or the failure of one of the FC adapters.
The built-in load balancing feature automatically distributes the workload across all controllers and I/O modules. In Dorado V6, LUNs do not require binding to a controller, and the load on a single LUN is automatically distributed among all controllers and I/O modules.
To evaluate its effectiveness, we presented the test server with four LUNs and sequentially excluded one LUN from the system. During this process, all front-end interfaces and storage system controllers were utilized evenly.
System Component Failures
During the series of resilience tests, we created a background load on the array using Vdbench, with a rate of approximately 1 GB/s. The performance of the array was practically unaffected by either the failure of a single power line or the failure of one of the FC adapters.
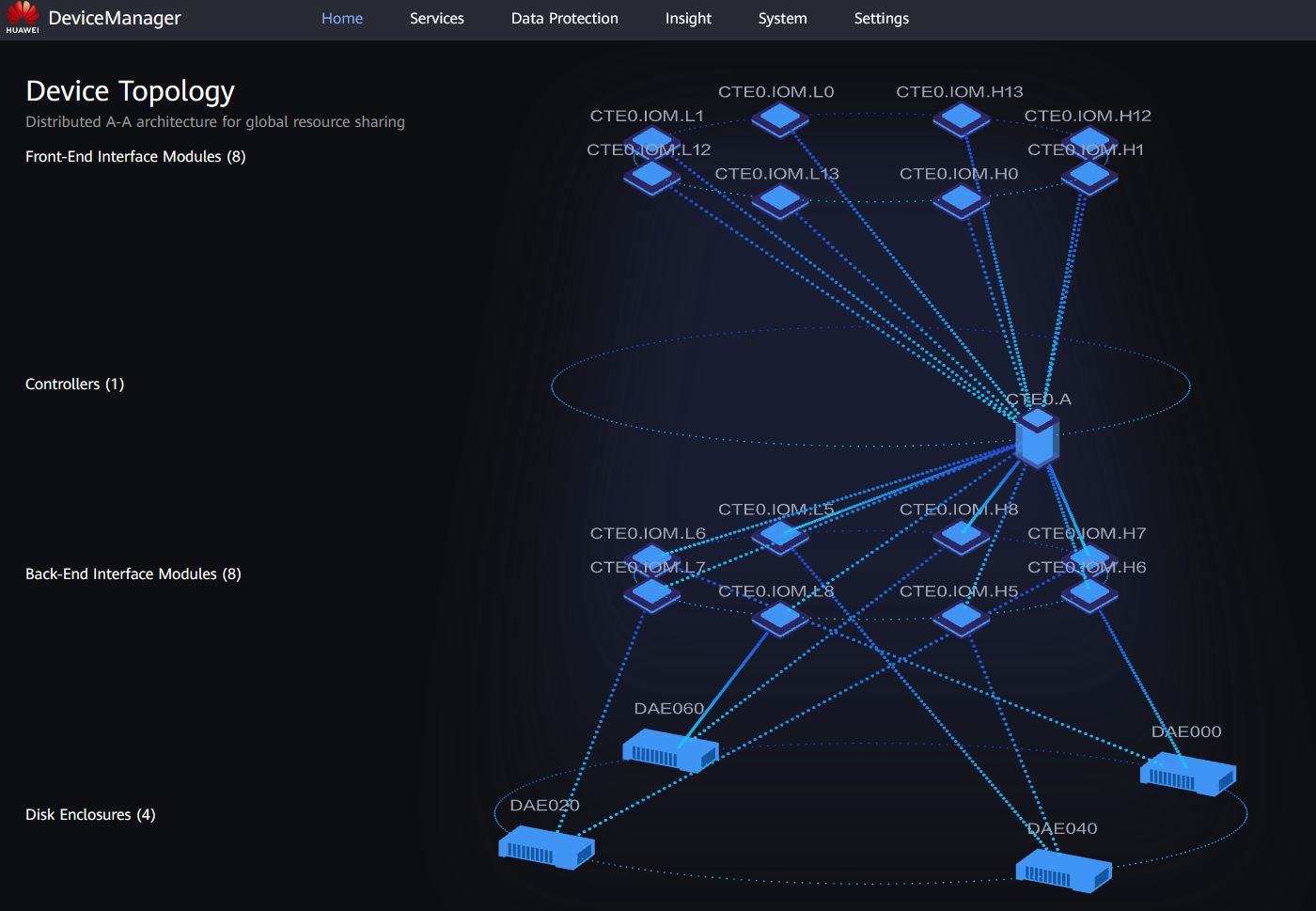
Another interesting resilience feature is the ability to operate with the failure of three out of four controllers. The architectural peculiarity of the Dorado 18000 V6 is that each controller inside the chassis has a connection to all back-end and front-end I/O modules.
Thus, controller failure or the execution of scheduled maintenance procedures or storage system updates, which involve controller restarts, do not lead to events requiring the operation of the MPIO driver on the host side.
Thus, controller failure or the execution of scheduled maintenance procedures or storage system updates, which involve controller restarts, do not lead to events requiring the operation of the MPIO driver on the host side.
The images below compare the topology of Dorado 18000 V6 in a state with four functional controllers and in a state with one functional controller. In both cases, it is evident that the number of serviced front-end interfaces remains unchanged. From the host's perspective, all paths are active and accessible. The same applies to back-end connections to the disk shelves.

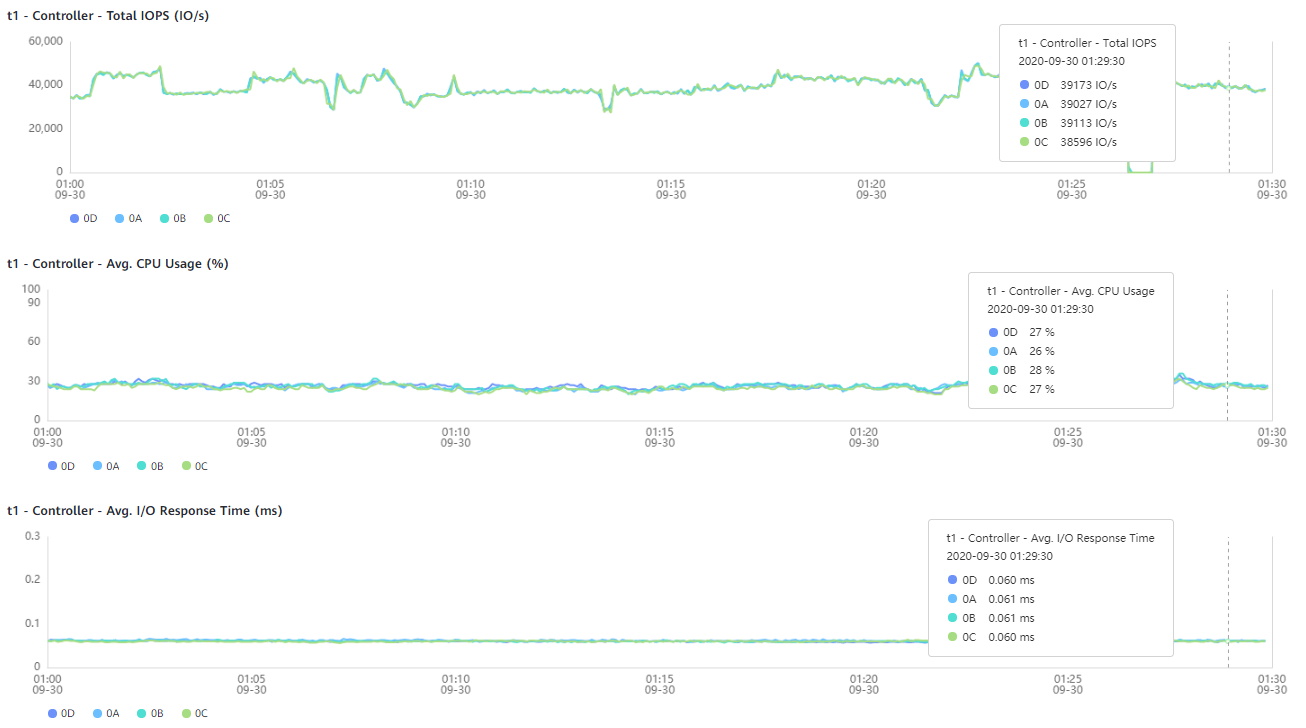
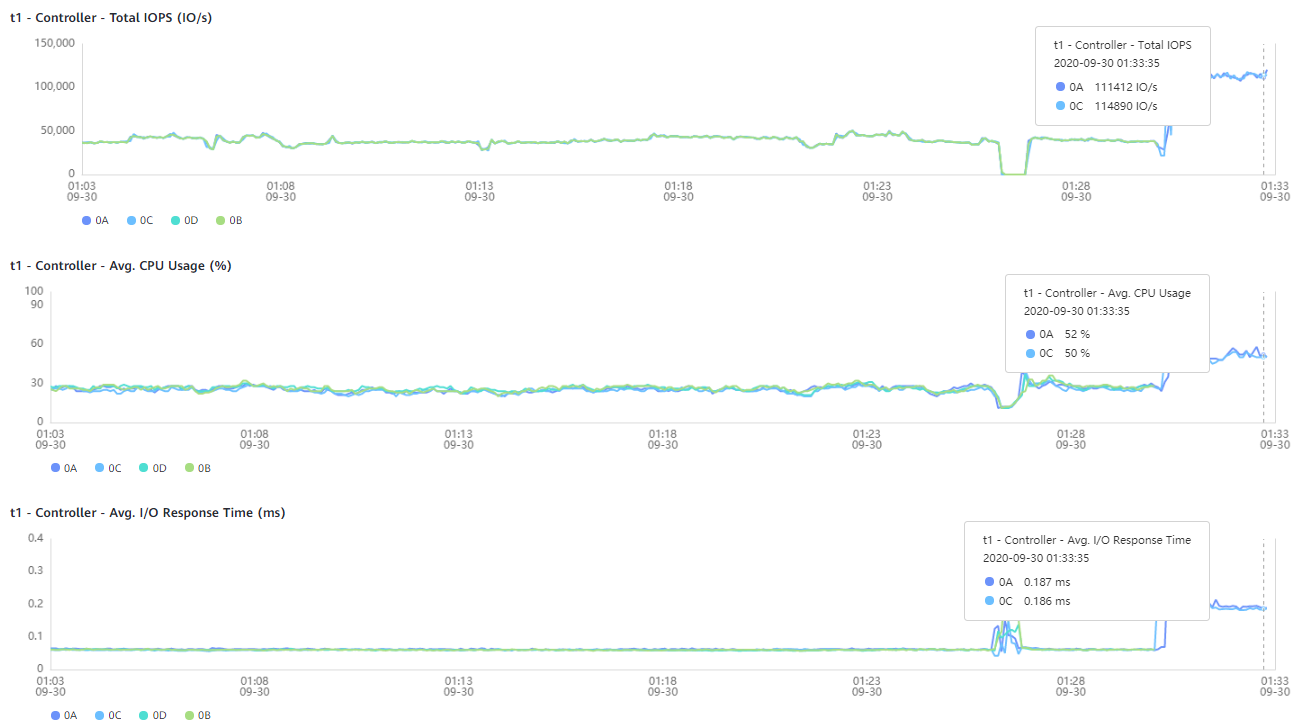
In the graphs below, the normal operation of all controllers is shown, as well as the performance indicators during the failure of two controllers and during the failure of three controller

In the event of a failure disk
In the event of a failure of one or several disks, the system starts the pool reconstruction process and performs it in the background. In Dorado V6, RAID is built on chunks, and the reserve capacity for hot swapping is distributed across all disks. Dorado can use both a special reserve and the free capacity of the disk pool for rebuilds. We verified data availability during the simultaneous failure of three disks for a pool with RAID-TP and measured the disk reconstruction time in RAID6 under load.
First, a pool of 60 disks with a capacity of 1.92 TB each was initialized in RAID6. A background load on the storage system was created using Vdbench – 140,000 IOPS, 65R/35W 8K profile, 1.1 GB/s. The duration of the reconstruction of a single 1.92 TB disk under such a load was 69 minutes. The graph below shows the spike in latency during the disk failure.
In the event of a failure of one or several disks, the system starts the pool reconstruction process and performs it in the background. In Dorado V6, RAID is built on chunks, and the reserve capacity for hot swapping is distributed across all disks. Dorado can use both a special reserve and the free capacity of the disk pool for rebuilds. We verified data availability during the simultaneous failure of three disks for a pool with RAID-TP and measured the disk reconstruction time in RAID6 under load.
First, a pool of 60 disks with a capacity of 1.92 TB each was initialized in RAID6. A background load on the storage system was created using Vdbench – 140,000 IOPS, 65R/35W 8K profile, 1.1 GB/s. The duration of the reconstruction of a single 1.92 TB disk under such a load was 69 minutes. The graph below shows the spike in latency during the disk failure.
Then, we set up a pool with the same 60 disks with a capacity of 1.92 TB each in RAID-TP configuration. With the simultaneous failure of three disks, the pool reconstruction time without background load was 28 minutes.
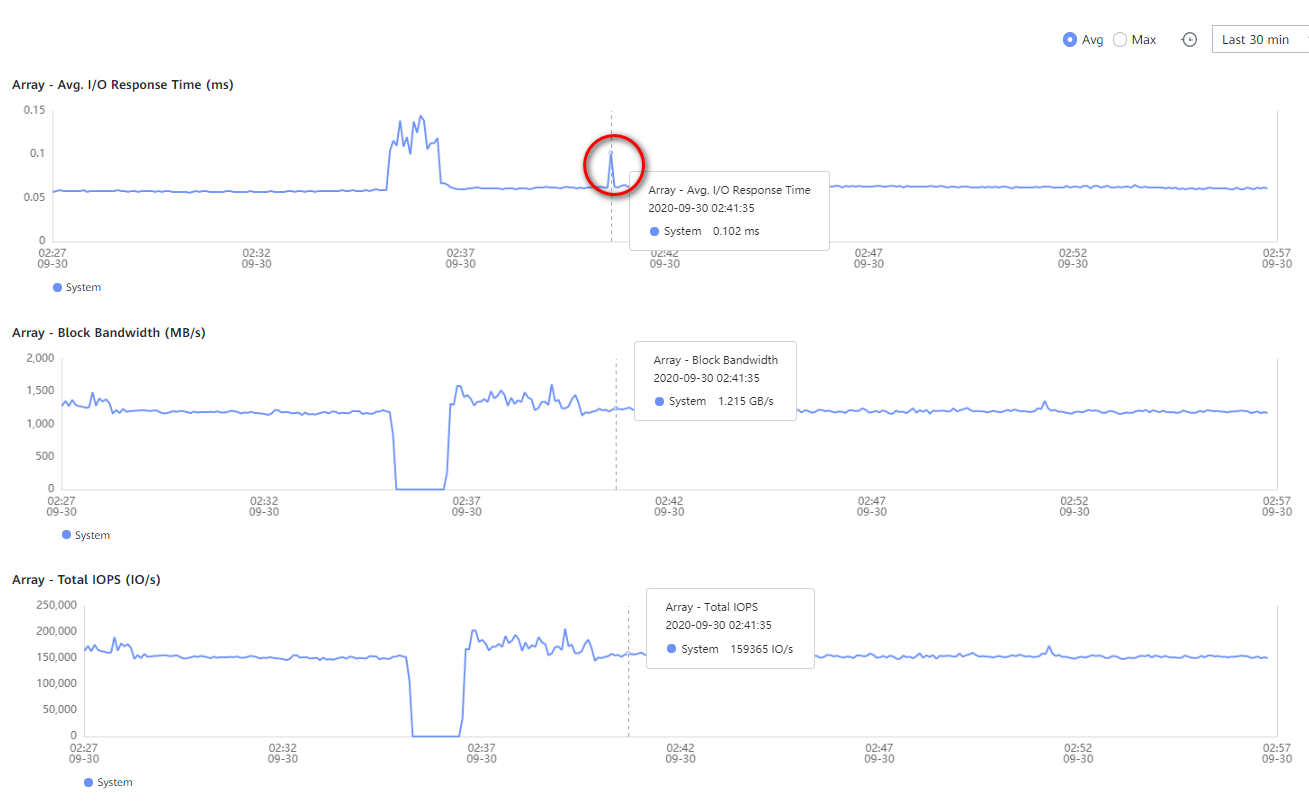
The mysterious situation arose at the very beginning of the testing phase. After connecting the Dorado 5000 V6, a lower-end model, to the test server running AIX 7.1 OS, we immediately achieved the maximum possible performance for the storage system, which matched the calculated maximum in the sizing tool.
However, the performance of Dorado 18000 V6 turned out to be several times lower than that of Dorado 5000 V6! As it turned out, the issue wasn't with the storage system. The AIX scheduler, when experiencing rapid growth in I/O load and an increase in the number of threads, began to shape the queue down to two commands per LUN, which led to a significant drop in performance, almost by an order of magnitude! We were getting around 80,000 IOPS instead of the expected million-plus.
This case highlights the importance of understanding the interactions between the storage system and the host operating system, as well as the need to identify and address any bottlenecks or limitations in the I/O path to ensure optimal performance. In this instance, the problem was not with the storage system itself but rather with the AIX scheduler's handling of the I/O load.
However, the performance of Dorado 18000 V6 turned out to be several times lower than that of Dorado 5000 V6! As it turned out, the issue wasn't with the storage system. The AIX scheduler, when experiencing rapid growth in I/O load and an increase in the number of threads, began to shape the queue down to two commands per LUN, which led to a significant drop in performance, almost by an order of magnitude! We were getting around 80,000 IOPS instead of the expected million-plus.
This case highlights the importance of understanding the interactions between the storage system and the host operating system, as well as the need to identify and address any bottlenecks or limitations in the I/O path to ensure optimal performance. In this instance, the problem was not with the storage system itself but rather with the AIX scheduler's handling of the I/O load.
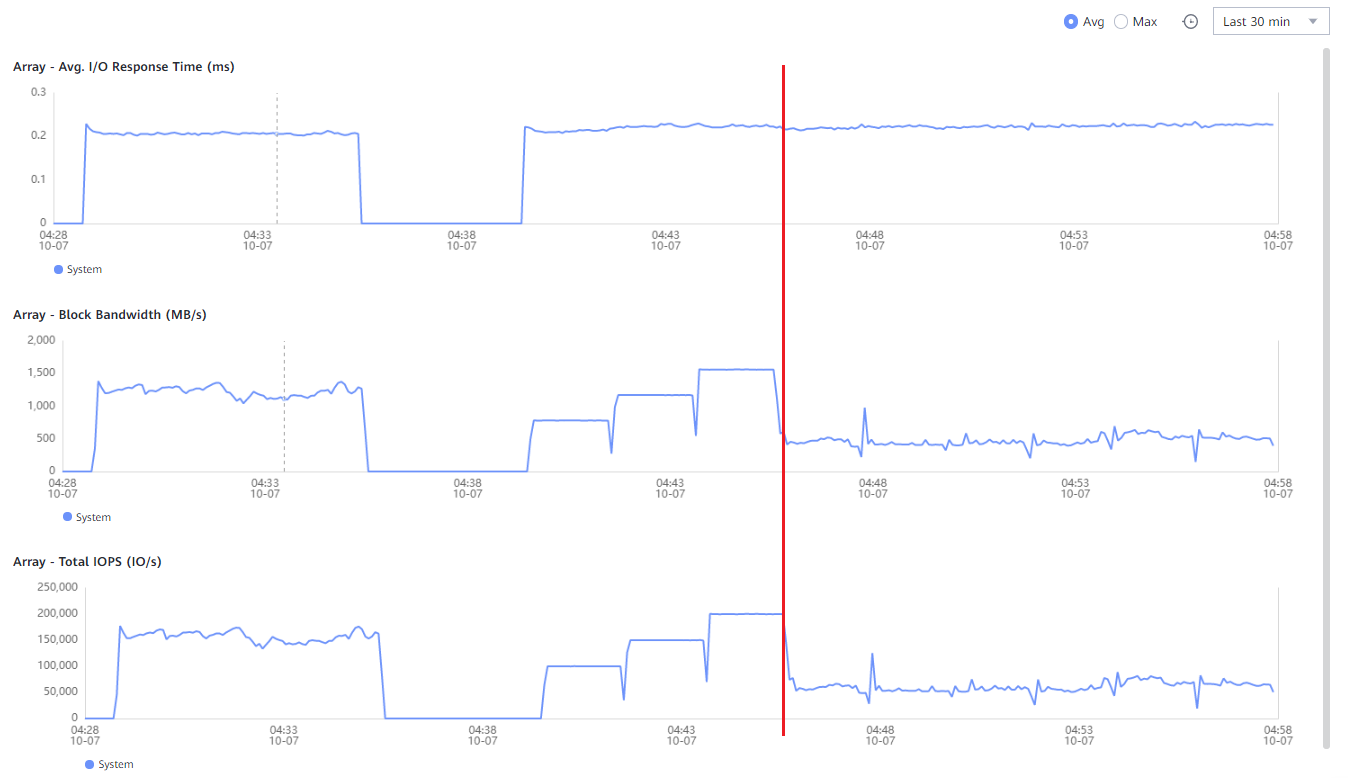
After checking everything again, we found no issues with AIX 7.2: the 18000 V6 worked like a charm. Considering that everything also worked perfectly with Linux and VMware, we continued troubleshooting. It was important to find a solution specifically for AIX 7.1 since the company for which we were conducting the tests did not plan to massively upgrade their AIX servers to a newer OS version. The IBM AIX Performance Management Guide's 500 pages did not provide any clues.
On their part, Huawei managed to set up a similar test environment within a few days and replicated our issue. They then concluded that the storage system itself and Huawei's ODM drivers were not the cause of the problem.
The case escalated to IBM's third-line support. An expert with experience in developing drivers for AIX joined the investigation. We had to collect a "ton" of perfpmr logs and conduct a series of repeated tests with various combinations of parameters, including: FC adapter firmware, storage system driver version, HBA parameters, LUN parameters, different I/O path balancing mechanisms, different OS service packs, Java version, alternative benchmarks such as xdisk, ndisk, and dd. Of course, we checked the SAN at the very beginning.
On their part, Huawei managed to set up a similar test environment within a few days and replicated our issue. They then concluded that the storage system itself and Huawei's ODM drivers were not the cause of the problem.
The case escalated to IBM's third-line support. An expert with experience in developing drivers for AIX joined the investigation. We had to collect a "ton" of perfpmr logs and conduct a series of repeated tests with various combinations of parameters, including: FC adapter firmware, storage system driver version, HBA parameters, LUN parameters, different I/O path balancing mechanisms, different OS service packs, Java version, alternative benchmarks such as xdisk, ndisk, and dd. Of course, we checked the SAN at the very beginning.
Eventually, we found the "spoon." To make AIX 7.1 work properly with very fast "raw" disks, it was necessary to change the value of the spec_accessupdate parameter. Strangely, this parameter is not mentioned in the AIX Performance Management Guide and is almost unsearchable on Google. Its description in the operating system's context Help is very brief. It turned out that AIX 7.1 and AIX 7.2 have different default values for this parameter.
By modifying the spec_accessupdate parameter, we were able to resolve the performance issue with AIX 7.1 and ensure that the Dorado 18000 V6 storage system worked efficiently with the older operating system. This highlights the importance of understanding how different configurations and settings can impact performance and the need for thorough troubleshooting to identify and address any issues:
Purpose: Indicates for devices how timestamp changes are reflected.Values:
By setting the spec_accessupdate parameter to 2, we achieved stable and high performance of the AIX 7.1 disk input/output subsystem in all subsequent tests.
ioo -p -o spec_accessupdate=2
By modifying the spec_accessupdate parameter, we were able to resolve the performance issue with AIX 7.1 and ensure that the Dorado 18000 V6 storage system worked efficiently with the older operating system. This highlights the importance of understanding how different configurations and settings can impact performance and the need for thorough troubleshooting to identify and address any issues:
Purpose: Indicates for devices how timestamp changes are reflected.Values:
- 0 is standards-compliant behavior (default in AIX 7.1)
- 1 indicates access and update times are not changed
- 2 indicates lazy access/update changes (default in AIX 7.2)
By setting the spec_accessupdate parameter to 2, we achieved stable and high performance of the AIX 7.1 disk input/output subsystem in all subsequent tests.
ioo -p -o spec_accessupdate=2
Since Oracle ASM works specifically with raw disks, the correct value for the spec_accessupdate parameter in AIX 7.1 can significantly improve the performance of database disk operations.
Huawei Dorado V6: A Comprehensive Storage Review
We conducted an extensive review of the Huawei Dorado V6 storage system, testing its performance, resilience, and functionality. The Dorado V6 is Huawei's latest storage offering, and is designed to compete with similar offerings from other vendors.
Huawei Dorado V6: A Comprehensive Storage Review
We conducted an extensive review of the Huawei Dorado V6 storage system, testing its performance, resilience, and functionality. The Dorado V6 is Huawei's latest storage offering, and is designed to compete with similar offerings from other vendors.
We began by testing the system's performance, using a range of benchmarks and real-world workloads. We found that the Dorado V6 delivered exceptional performance, with high IOPS and low latency. The system is also highly scalable, with the ability to add more drives and controllers as needed.
We then tested the system's resilience, running simulations of multiple drive failures to see how the system coped. We found that the Dorado V6 was able to recover quickly from failures, and that data was not lost or corrupted during the process.
Finally, we examined the system's functionality, looking at its management interface, configuration options, and support for different protocols and applications. We found that the Dorado V6 was easy to manage and configure, with a comprehensive set of tools and features. The system also supports a wide range of protocols and applications, making it a versatile storage solution for businesses of all sizes.
Overall, we were impressed with the Huawei Dorado V6, and would recommend it to any business looking for a high-performance, resilient, and functional storage system.
We then tested the system's resilience, running simulations of multiple drive failures to see how the system coped. We found that the Dorado V6 was able to recover quickly from failures, and that data was not lost or corrupted during the process.
Finally, we examined the system's functionality, looking at its management interface, configuration options, and support for different protocols and applications. We found that the Dorado V6 was easy to manage and configure, with a comprehensive set of tools and features. The system also supports a wide range of protocols and applications, making it a versatile storage solution for businesses of all sizes.
Overall, we were impressed with the Huawei Dorado V6, and would recommend it to any business looking for a high-performance, resilient, and functional storage system.